|
Chonghao Sima (司马崇昊) Chonghao Sima is a Ph.D. student in Computer Science at The University of Hong Kong (HKU), working at MMLab@HKU, advised by Prof. Ping Luo and Prof. Hongyang Li. He closely works with Kashyap Chitta and Prof. Andreas Geiger. His research focuses on autonomous driving and embodied AI, spanning 3D perception, end-to-end planning, vision-language models for driving, and robot manipulation. He received his B.S. from Huazhong University of Science and Technology (2015–2019), then moved to the US to pursue his Ph.D. at Purdue University (2019–2023) with Prof. Yexiang Xue, before transferring to HKU in 2023. He has interned at NVIDIA Autonomous Vehicle Applied Research with Dr. Jose M. Alvarez and Dr. Zhiding Yu, and at OpenDriveLab, Shanghai AI Lab. He was a core contributor to UniAD, which received the CVPR 2023 Best Paper Award (1/9155), and received Best Paper Finalist (29/4306) at IROS 2025 and Outstanding Reviewer (232/7000) at CVPR 2023. He won the Waymo Open Challenge 2022 and hosted challenges at CVPR 2024 Autonomous Grand Challenge (DriveLM) and CVPR 2023 Autonomous Driving Challenge (3D Occupancy Prediction). He holds 3 US patents, organizes workshops at CVPR and ICLR, and reviews for CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, ICRA, IROS, T-PAMI, and IJCV. Email / CV / Google Scholar / GitHub / Twitter / Bluesky / LinkedIn |

|
PublicationsI believe in building benchmarks to accelerate the research cycle in the community, and a good module should be scalably applicable in real-world scenarios. My research addresses the curse of reality for physical agents — the challenge that the real world will always present conditions a model has never seen. I organize my work around four research questions spanning the perceive-reason-act loop:
Some papers are highlighted. |
|
Architecture End-to-end systems with self-correction |
|
|
Intelligent Robot Manipulation Requires Self-Directed Learning
Li Chen, Chonghao Sima, Kashyap Chitta, Antonio Loquercio, Ping Luo, Yi Ma, Hongyang Li Authorea Preprints, 2025 paper / bibtex This Perspective argues that achieving human-level dexterity requires transcending imitation learning in favor of self-directed learning, which enables autonomous improvement in environments lacking resets or explicit rewards. We propose a framework structured around goal identification, skill acquisition, and performance evaluation, leveraging cross-modal synergies to navigate these algorithmic challenges. |
|
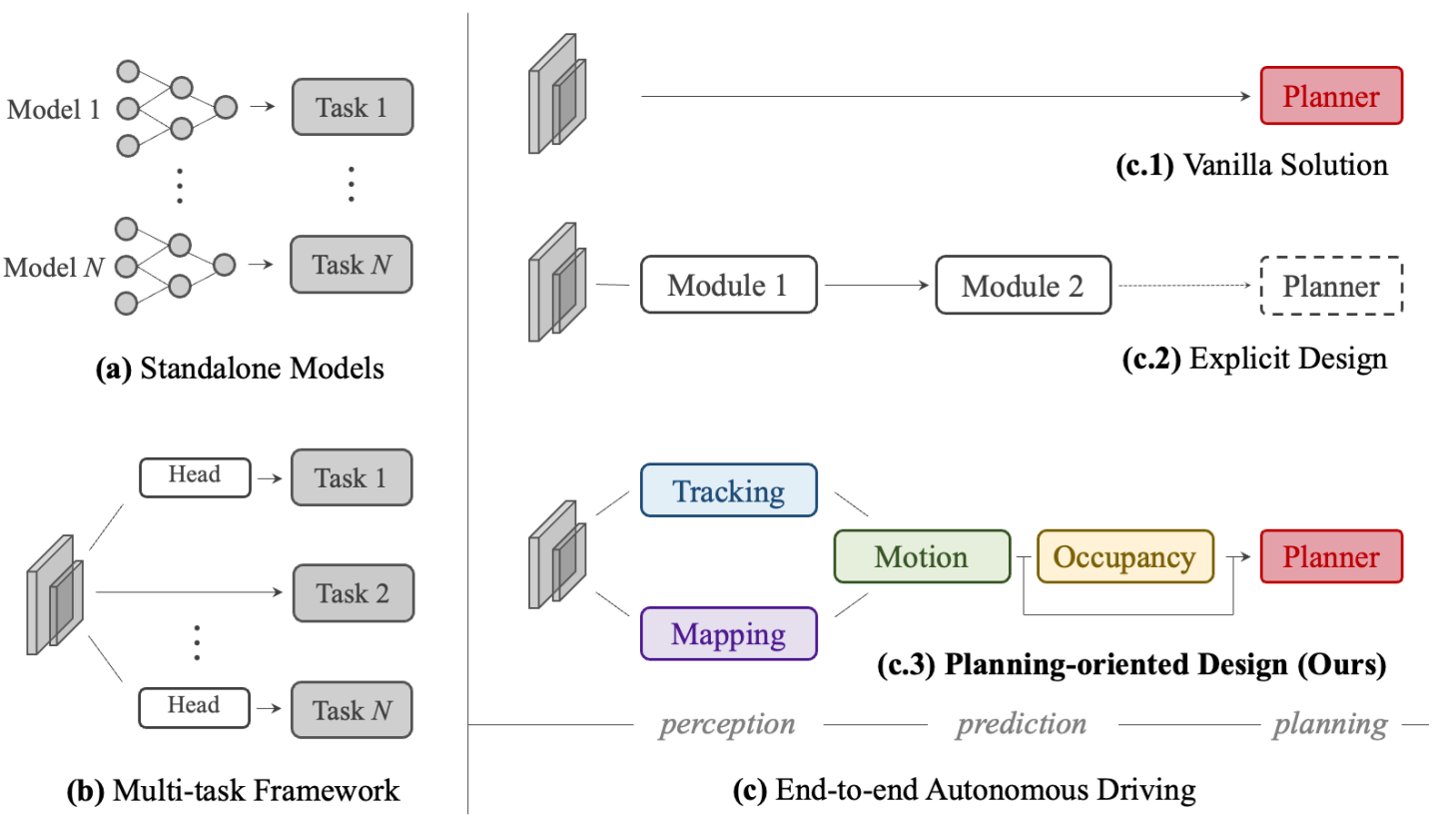
Planning-oriented Autonomous Driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, Hongyang Li CVPR, 2023 (Best Paper Award) paper / code  /
bibtex
/
bibtex
A unified end-to-end framework that hierarchically integrates full-stack driving tasks—perception, prediction, and planning—under a planning-oriented philosophy, achieving state-of-the-art across all tasks on nuScenes. |
|
Act Robust policy deployment under distributional shift |
|
|
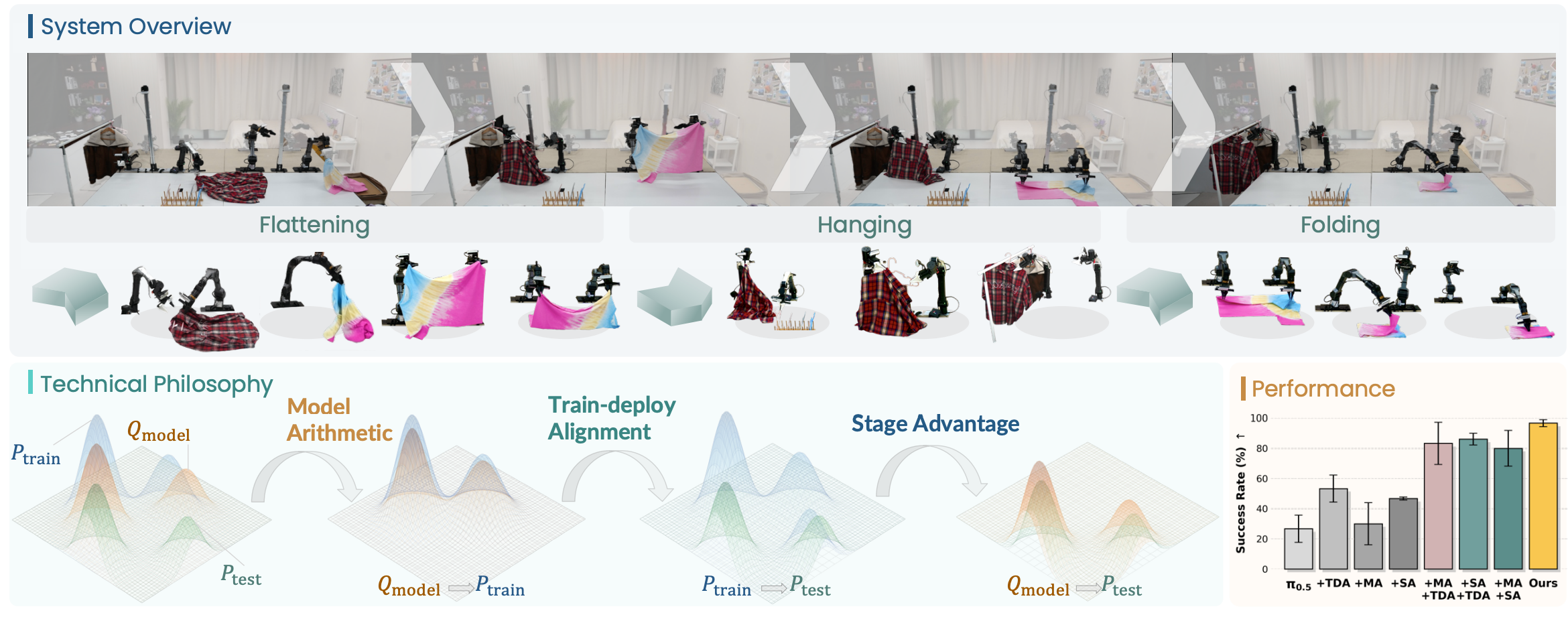
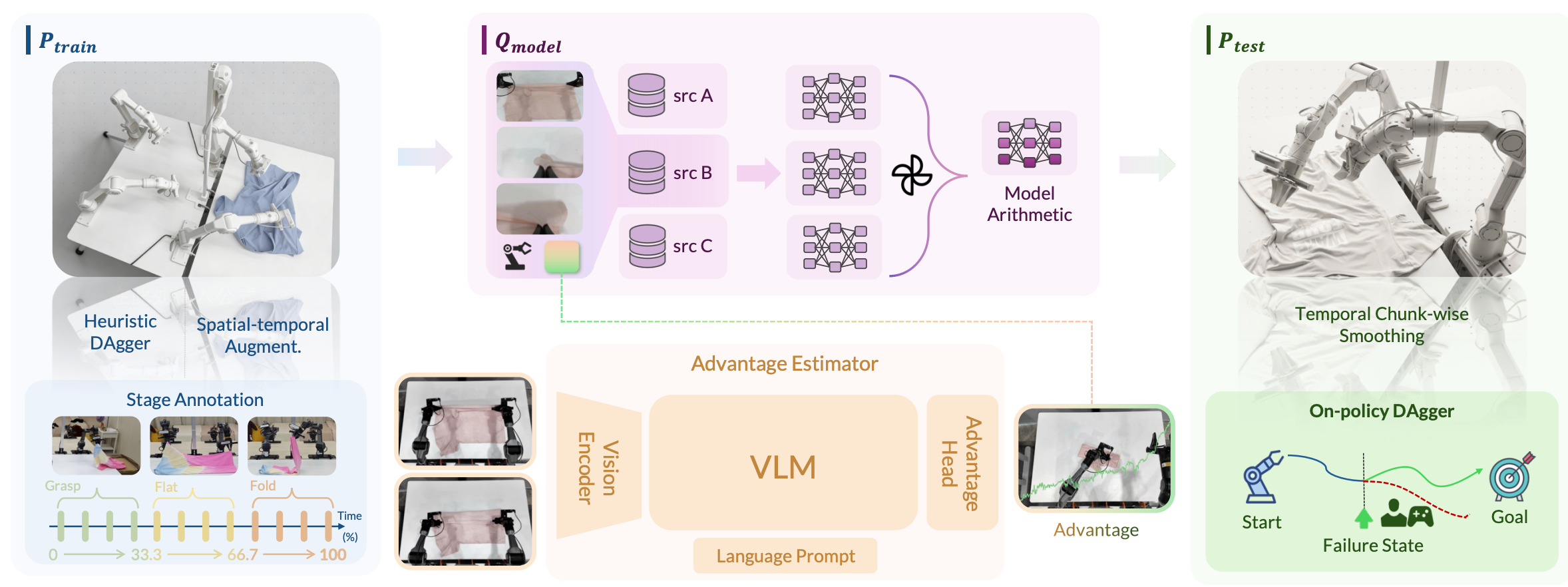
χ0: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
Chonghao Sima, Checheng Yu, Modi Shi, Lirui Zhao, et al arXiv preprint arXiv:2602.09021, 2026 project page / paper / code  /
bibtex
/
bibtex
We present χ0 to address distributional shifts across robot learning, through Model Arithmetic, Stage Advantage, and Train-Deploy Alignment. |
|
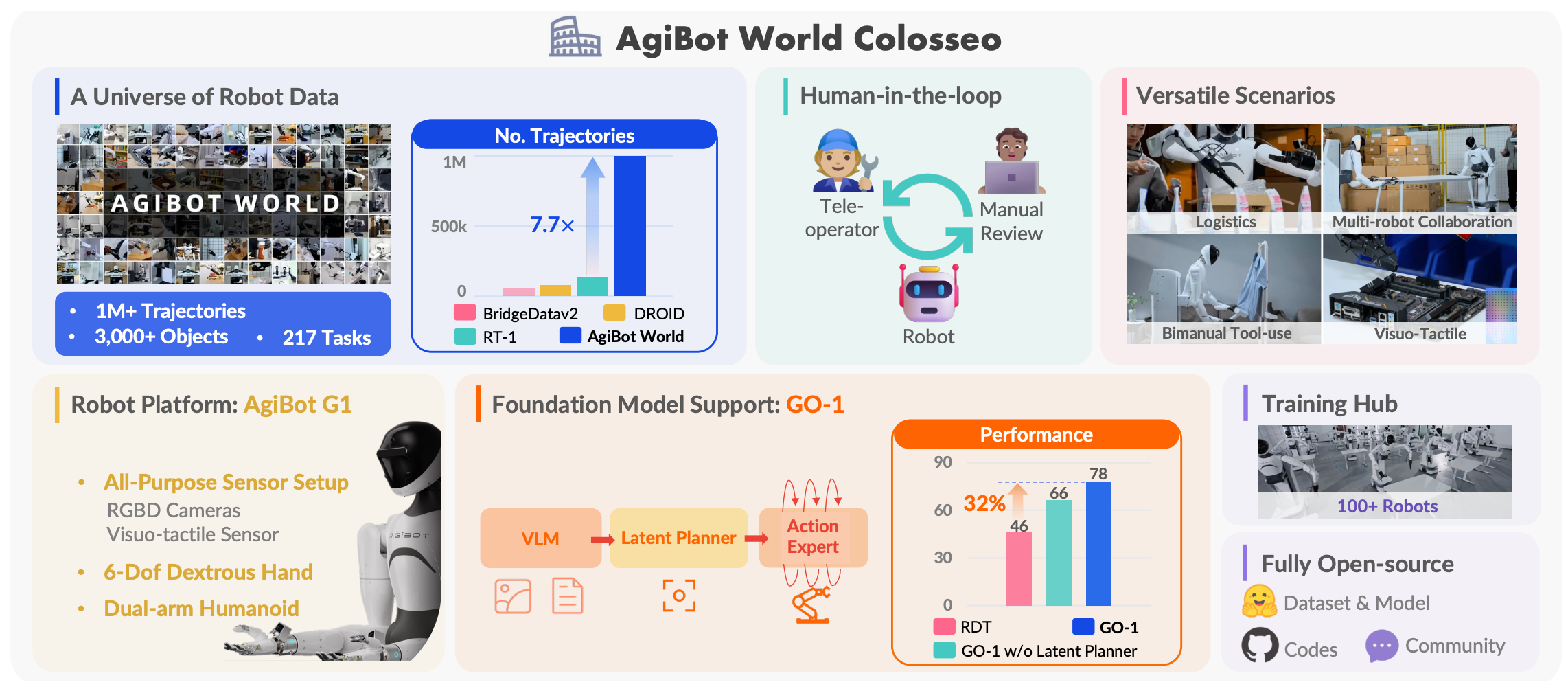
AgiBot World Colosseo: A Large-Scale Manipulation Platform for Scalable and Intelligent Embodied Systems
AgiBot-World-Contributors, Chonghao Sima, et al IROS, 2025 (Best Paper Finalist) project page / paper / code  /
challenge
/
bibtex
/
challenge
/
bibtex
AgiBot World aspires to transform large-scale robot learning and advance scalable robotic systems for production. This open-source platform invites researchers and practitioners to collaboratively shape the future of Embodied AI. |
|
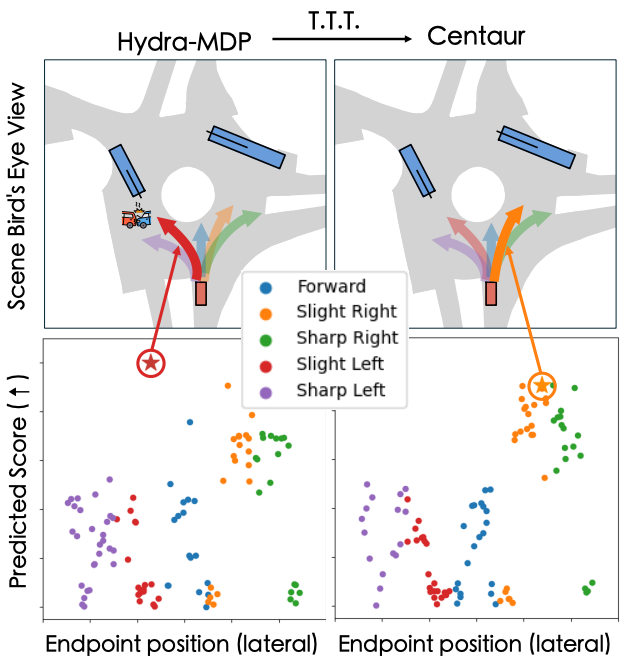
Centaur: Robust End-to-End Autonomous Driving with Test-Time Training
Chonghao Sima, Kashyap Chitta, Zhiding Yu, Shiyi Lan, Ping Luo, Andreas Geiger, Hongyang Li, Jose M. Alvarez arXiv preprint arXiv:2503.11650, 2025 paper / bibtex A test-time training framework for end-to-end driving that minimizes a novel Cluster Entropy uncertainty measure, improving planner robustness without hand-engineered rules or cost functions. Ranks 1st on the NAVSIM leaderboard at the time of submission. |
|
Reason LLM-grounded real-time planning |
|
|
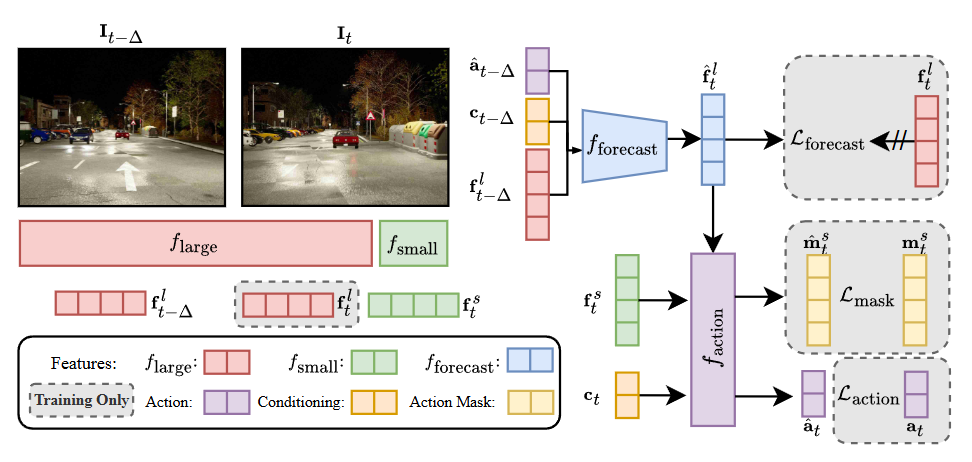
ETA: Efficiency Through Thinking Ahead, A Dual Approach to Self-Driving with Large Models
Shadi Hamdan, Chonghao Sima, Zetong Yang, Hongyang Li, Fatma Guney ICCV, 2025 paper / code  /
bibtex
/
bibtex
An asynchronous dual-system architecture that pairs a large model for anticipatory reasoning with a small model for real-time responsiveness, achieving state-of-the-art driving performance at near-real-time speed. |
|
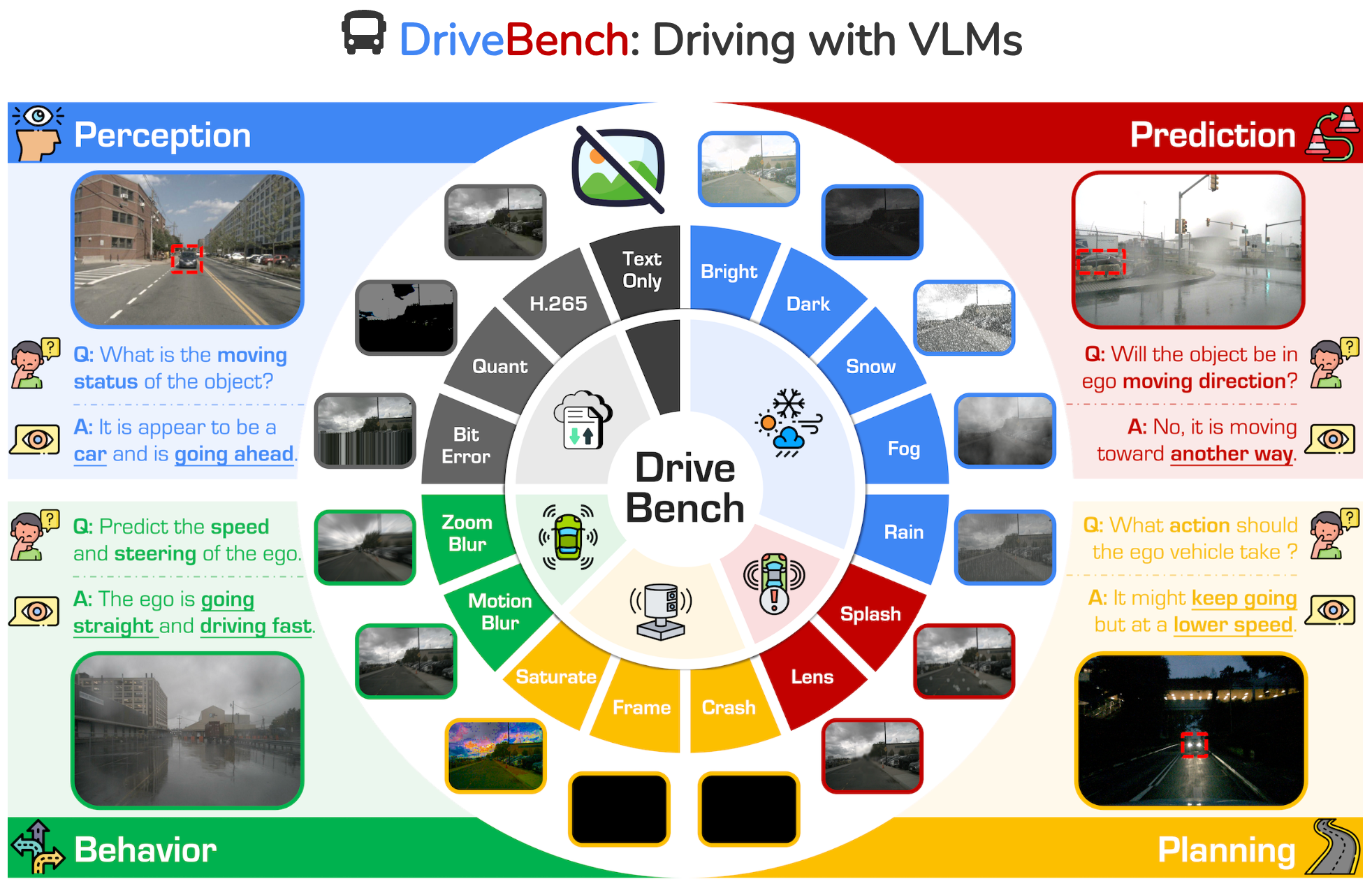
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, Liang Pan ICCV, 2025 project page / paper / code  /
leaderboard
/
bibtex
/
leaderboard
/
bibtex
DriveLM following work. A comprehensive benchmark evaluating the reliability of 12 VLMs for autonomous driving across 17 settings, revealing that current models often rely on textual cues rather than true visual grounding. |
|
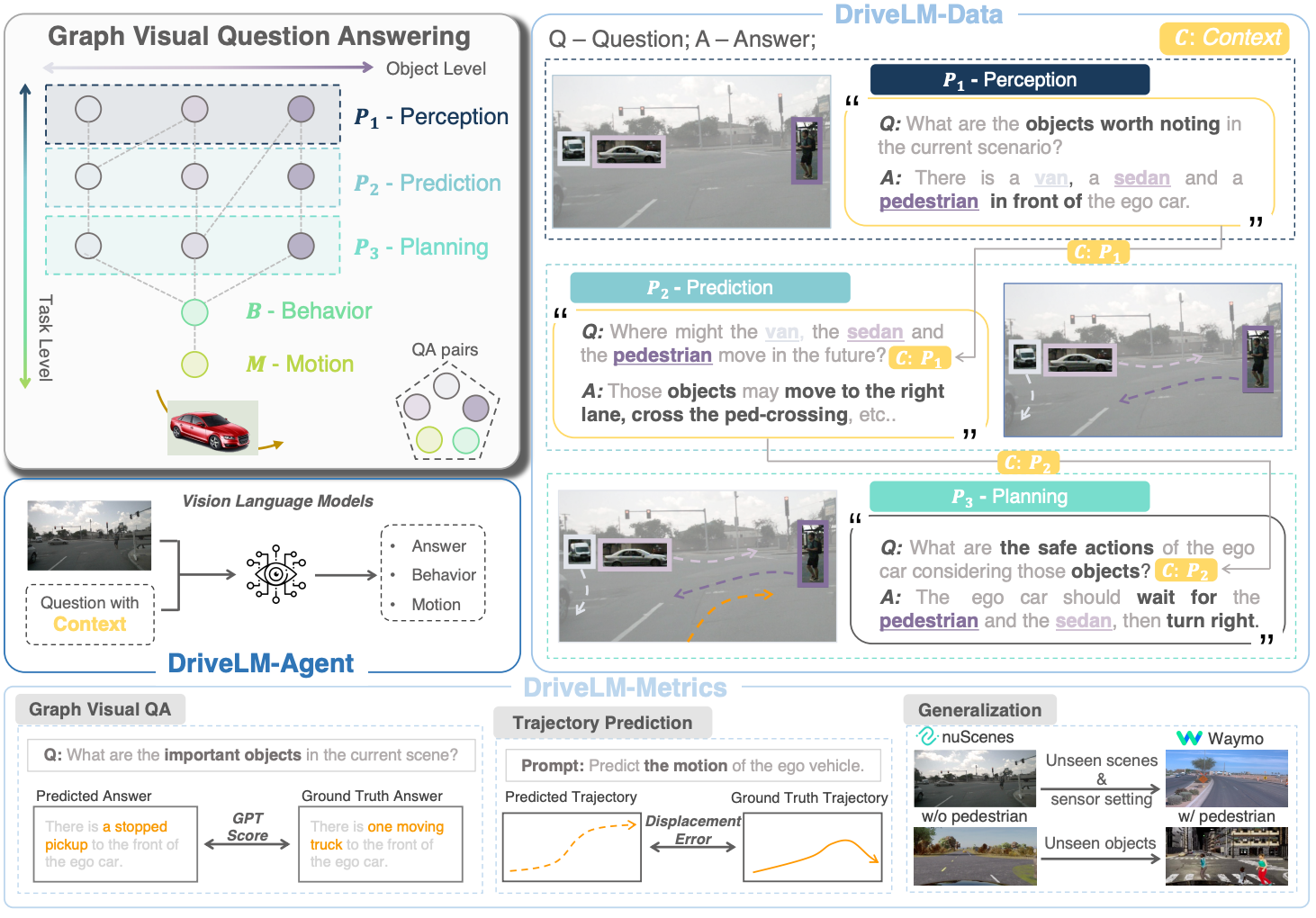
DriveLM: Driving with Graph Visual Question Answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, Hongyang Li ECCV, 2024 (Oral, 2.3%) project page / paper / code  /
challenge
/
bibtex
/
challenge
/
bibtex
A graph-structured VQA framework and dataset for integrating vision-language models into end-to-end driving, enabling multi-step reasoning through perception, prediction, and planning. |
|
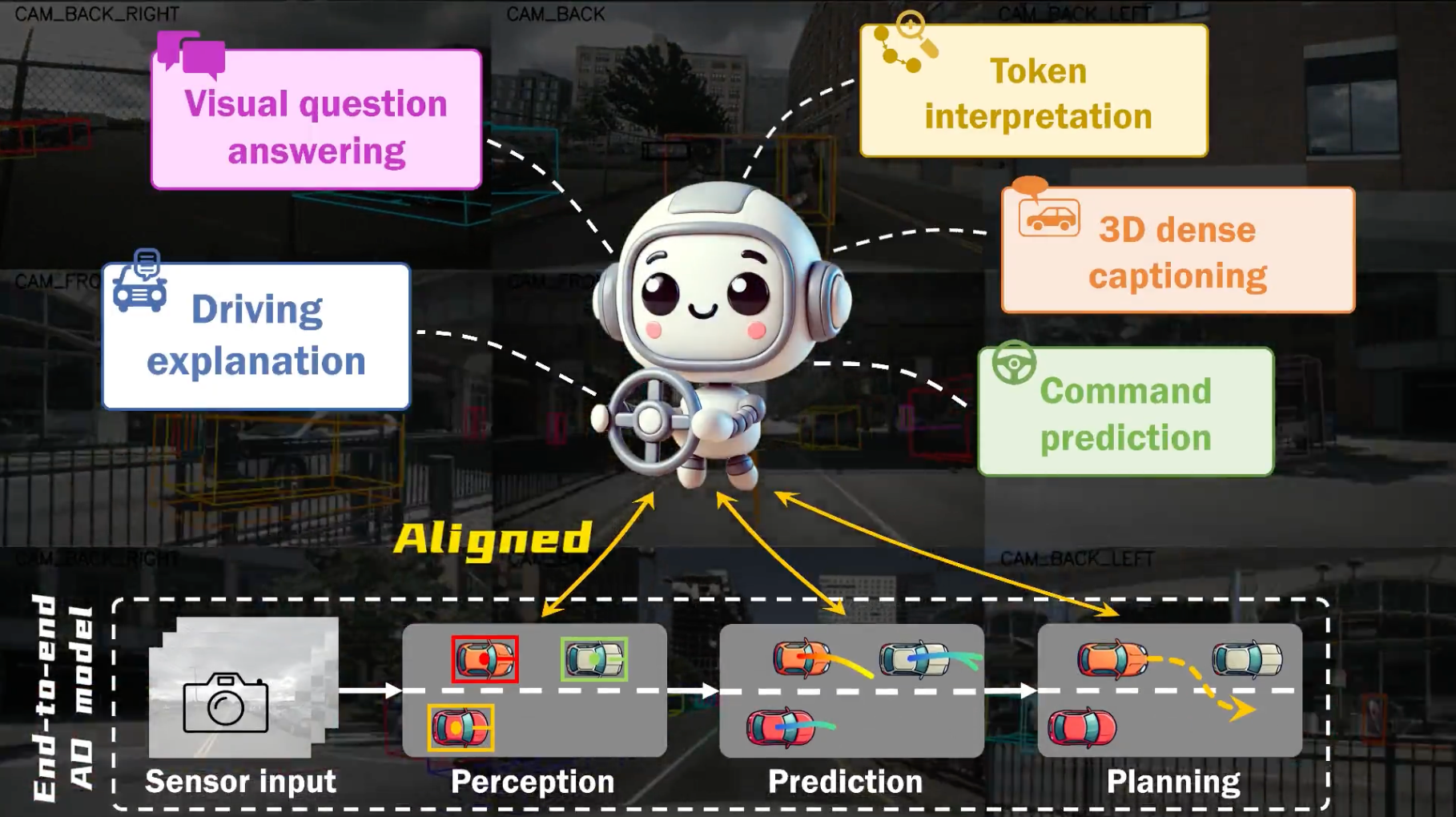
Hint-AD: Holistically Aligned Interpretability in End-to-End Autonomous Driving
Kairui Ding, Boyuan Chen, Yuchen Su, Huan-ang Gao, Bu Jin, Chonghao Sima, Wuqiang Zhang, Xiaohui Li, Paul Barsch, Hongyang Li, Hao Zhao CoRL, 2024 project page / paper / code  /
bibtex
/
bibtex
An integrated AD-language system that grounds natural language explanations in the model's intermediate perception, prediction, and planning outputs, with the human-labeled Nu-X dataset for driving explanation research. |
|
Perceive Universal 3D representations |
|

|
OpenScene: The Largest Up-to-Date 3D Occupancy Prediction Benchmark in Autonomous Driving
Chonghao Sima and OpenScene Contributors github.com/OpenDriveLab/OpenScene  , 2023
/
bibtex , 2023
/
bibtex
A compact redistribution of the large-scale nuPlan dataset, retaining only relevant annotations and sensor data at 2 Hz to reduce dataset size by over 10x. OpenScene spans 120+ hours of driving across Boston, Pittsburgh, Las Vegas, and Singapore with occupancy labels, and serves as the official dataset for the End-to-End Driving and Predictive World Model tracks at the CVPR 2024 and CVPR 2025 Autonomous Grand Challenges. |
|
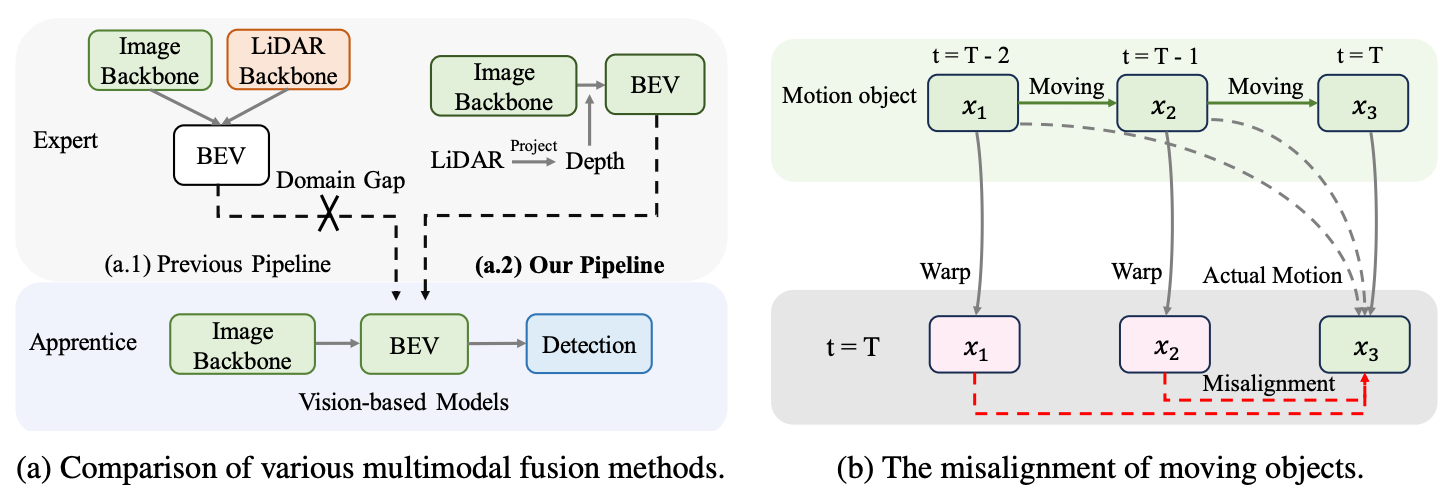
Leveraging Vision-Centric Multi-Modal Expertise for 3D Object Detection
Linyan Huang, Zhiqi Li, Chonghao Sima, Wenhai Wang, Jingdong Wang, Yu Qiao, Hongyang Li NeurIPS, 2023 paper / code  /
bibtex
/
bibtex
A vision-centric knowledge distillation framework (VCD) that bridges the LiDAR-camera domain gap with an apprentice-friendly multi-modal expert and trajectory-based temporal alignment, achieving 63.1% NDS on nuScenes with camera-only input. |
|
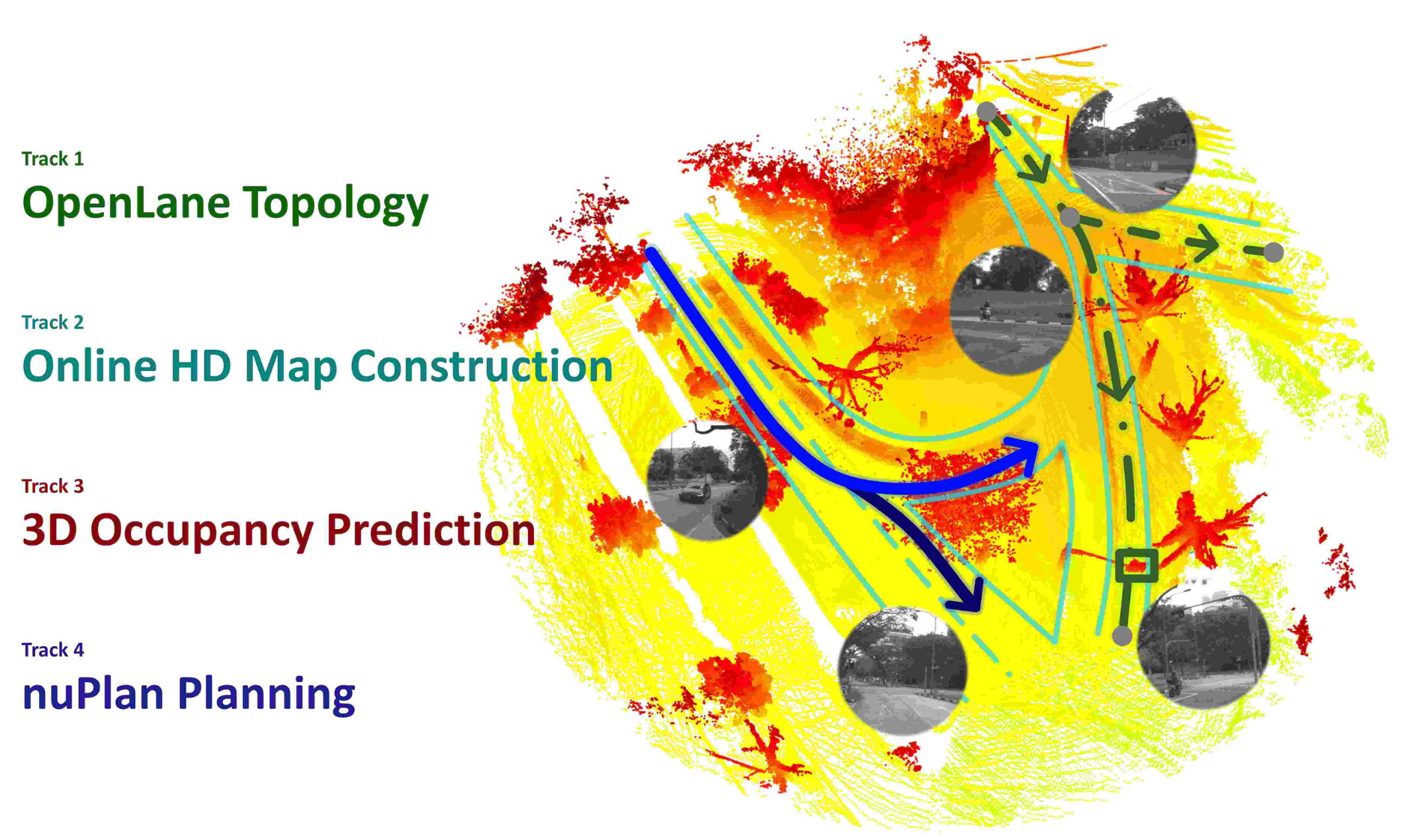
OpenLane-V2: A Topology Reasoning Benchmark for Unified 3D HD Mapping
Huijie Wang, Tianyu Li, Yang Li, Li Chen, Chonghao Sima, Zhenbo Liu, Bangjun Wang, Peijin Jia, Yuting Wang, Shengyin Jiang, Feng Wen, Hang Xu, Ping Luo, Junchi Yan, Wei Zhang, Hongyang Li NeurIPS, Datasets and Benchmarks Track, 2023 paper / code  /
challenge 2024
/
challenge 2023
/
bibtex
/
challenge 2024
/
challenge 2023
/
bibtex
The first benchmark for topology reasoning in driving scenes, requiring joint perception of 3D lanes and traffic elements together with their structural relationships to build a unified scene representation. |
|
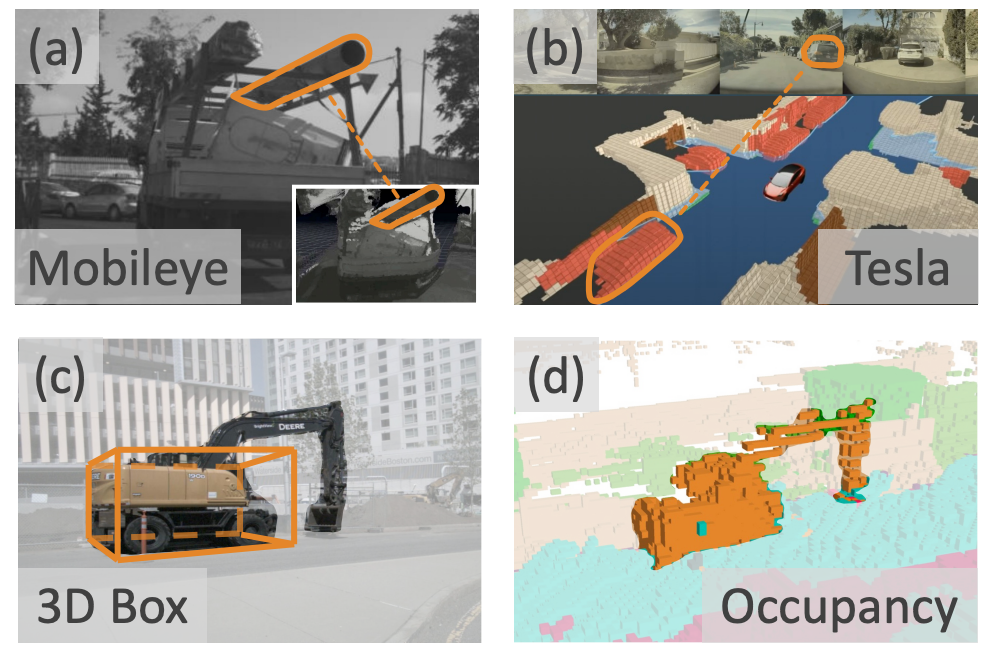
Scene as Occupancy
Chonghao Sima, Wenwen Tong, Tai Wang, Li Chen, Silei Wu, Hanming Deng, Yi Gu, Lewei Lu, Ping Luo, Dahua Lin, Hongyang Li ICCV, 2023 paper / code  /
challenge 2024
/
challenge 2023
/
bibtex
/
challenge 2024
/
challenge 2023
/
bibtex
A vision-centric 3D occupancy prediction framework that captures fine-grained scene geometry beyond bounding boxes, serving as a general representation for detection, segmentation, and planning on par with LiDAR-based methods. |
|
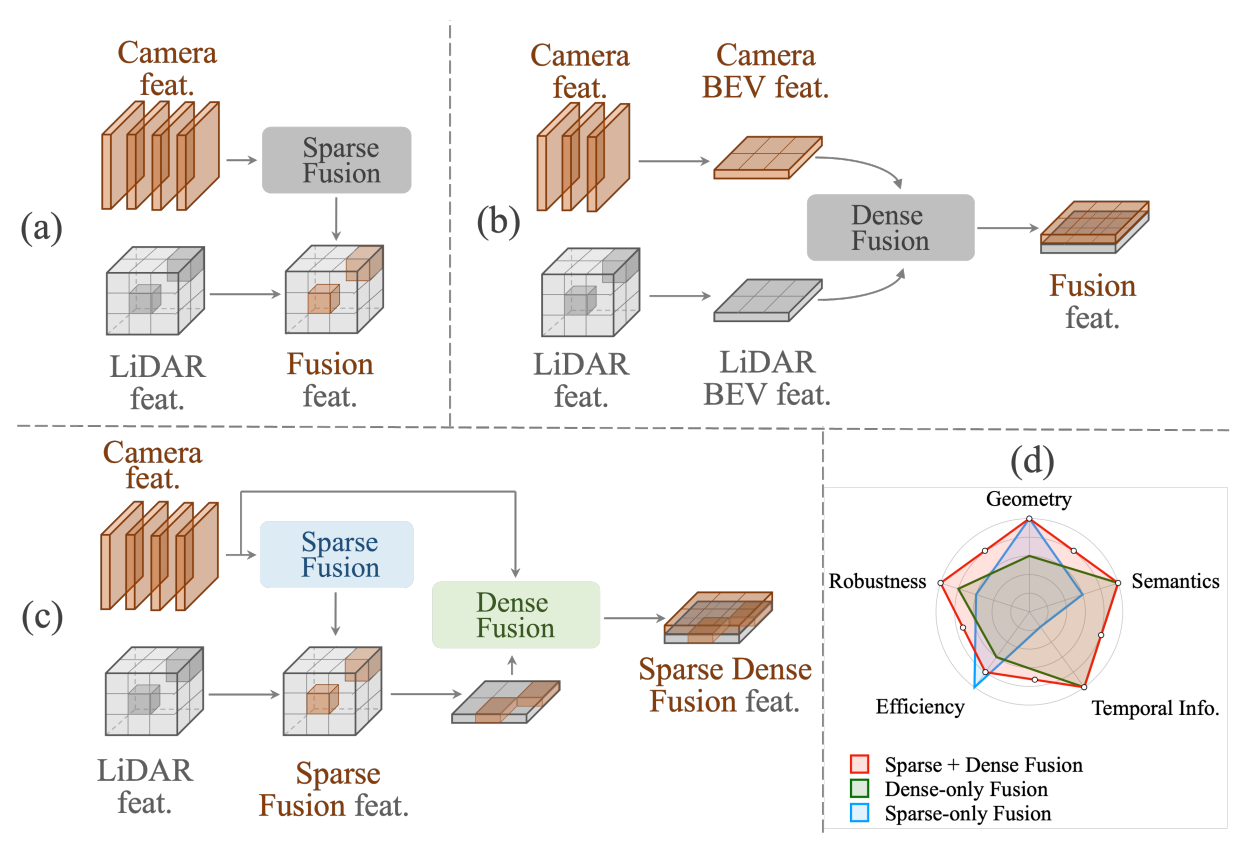
Sparse Dense Fusion for 3D Object Detection
Yulu Gao, Chonghao Sima, Shaoshuai Shi, Shangzhe Di, Si Liu, Hongyang Li IROS, 2023 paper / bibtex We propose Sparse Dense Fusion (SDF), a complementary framework that incorporates both sparse-fusion and dense-fusion modules via the Transformer architecture for camera-LiDAR 3D object detection, compensating the information loss in either manner. Through our SDF strategy, we outperform baseline by 4.3% in mAP and 2.5% in NDS, ranking first on the nuScenes benchmark. |
|
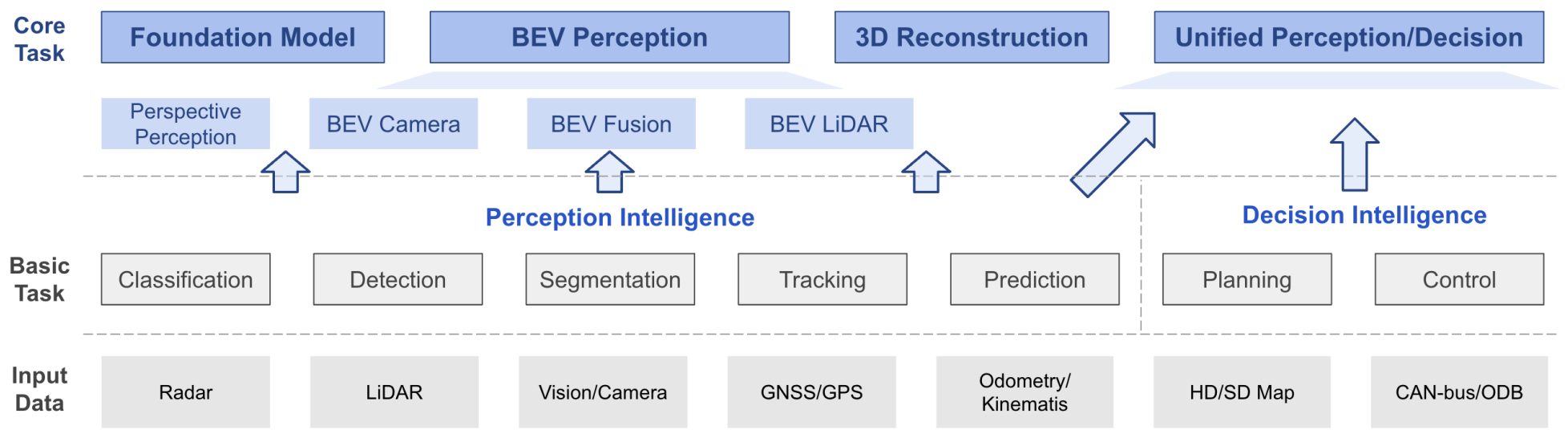
Delving Into the Devils of Bird's-Eye-View Perception: A Review, Evaluation and Recipe
Hongyang Li, Chonghao Sima, et al T-PAMI, 2023 paper / code
/
bibtex
A comprehensive survey and practical toolbox for bird's-eye-view perception across camera, LiDAR, and fusion modalities, with a bag of tricks that achieved 1st place on the Waymo Open Challenge 2022 camera-based detection track. |
|
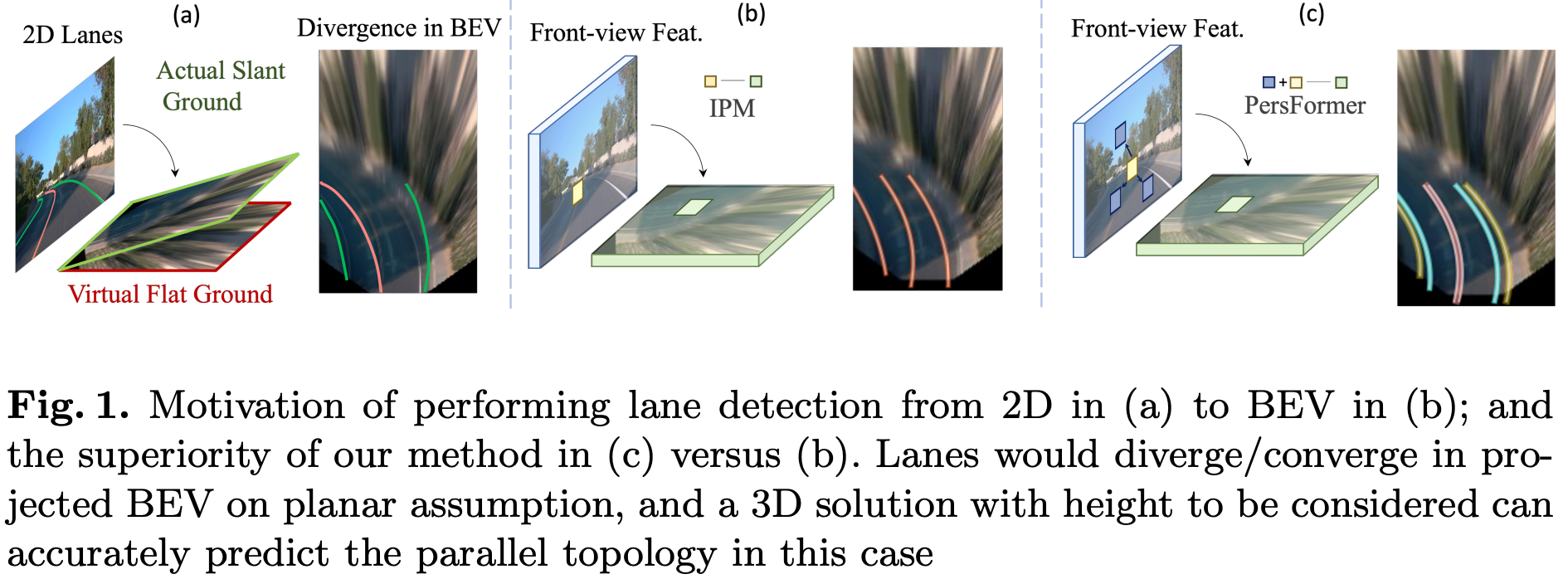
PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark
Li Chen, Chonghao Sima, Yang Li, Zehan Zheng, Jiajie Xu, Xiangwei Geng, Hongyang Li, Conghui He, Jianping Shi, Yu Qiao, Junchi Yan ECCV, 2022 (Oral, 2.3%) paper / code  /
data
/
third-party blog
/
bibtex
/
data
/
third-party blog
/
bibtex
We present PersFormer, an end-to-end monocular 3D lane detector with a novel Transformer-based spatial feature transformation module that generates BEV features by attending to related front-view local regions. PersFormer adopts a unified 2D/3D anchor design to detect 2D/3D lanes simultaneously. We also release OpenLane, one of the first large-scale real-world 3D lane datasets with 200K frames, 880K+ instance-level lanes, 14 categories, and diverse scenario annotations. |
|
BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, Jifeng Dai ECCV, 2022 paper / code  /
slides
/
bibtex
/
slides
/
bibtex
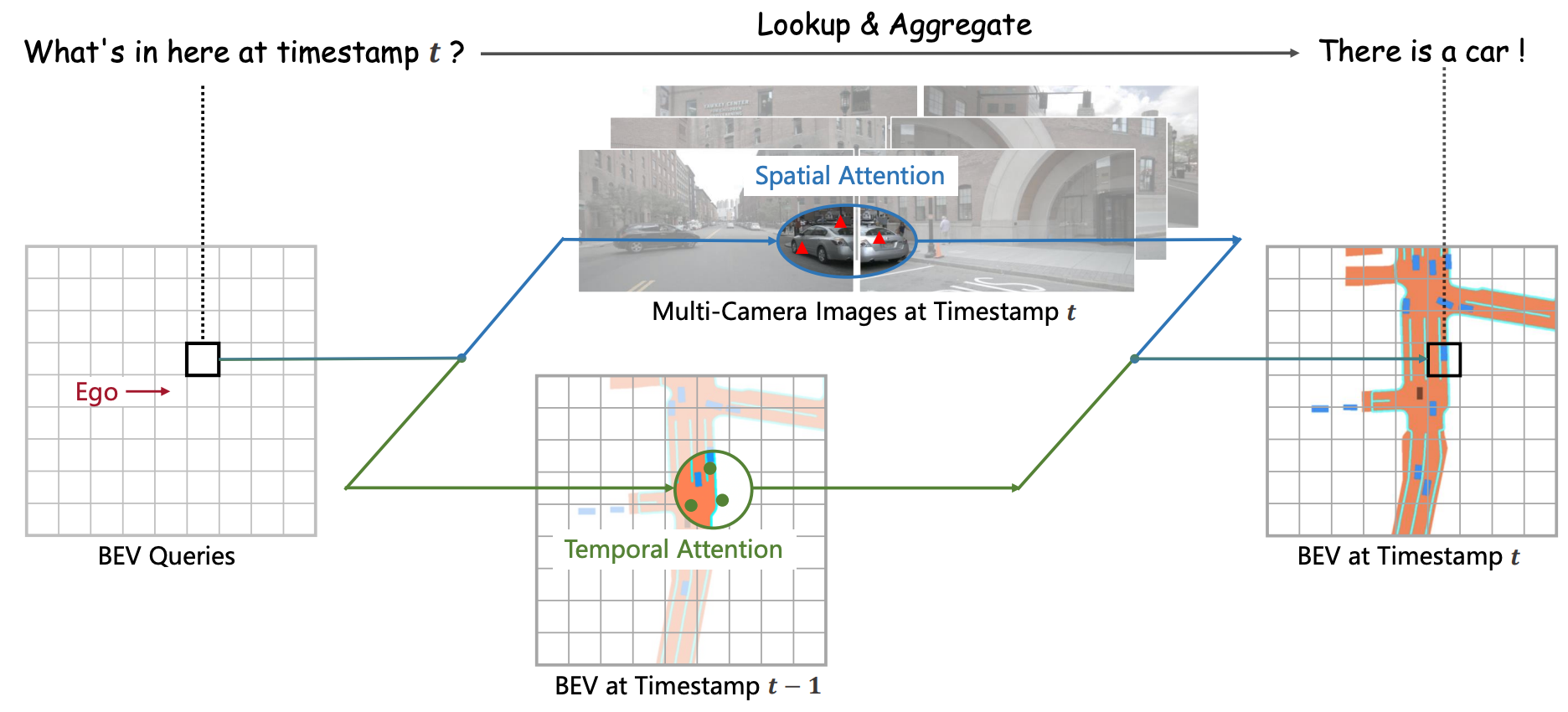
We present BEVFormer, which learns unified BEV representations with spatiotemporal transformers for multi-camera autonomous driving perception. BEVFormer exploits spatial cross-attention across camera views and temporal self-attention over history BEV features through predefined grid-shaped BEV queries. It achieves 56.9% NDS on nuScenes test, 9.0 points above prior art and on par with LiDAR-based methods. |
|
Earlier Work |
|
|
LSH-SMILE: Locality Sensitive Hashing Accelerated Simulation and Learning
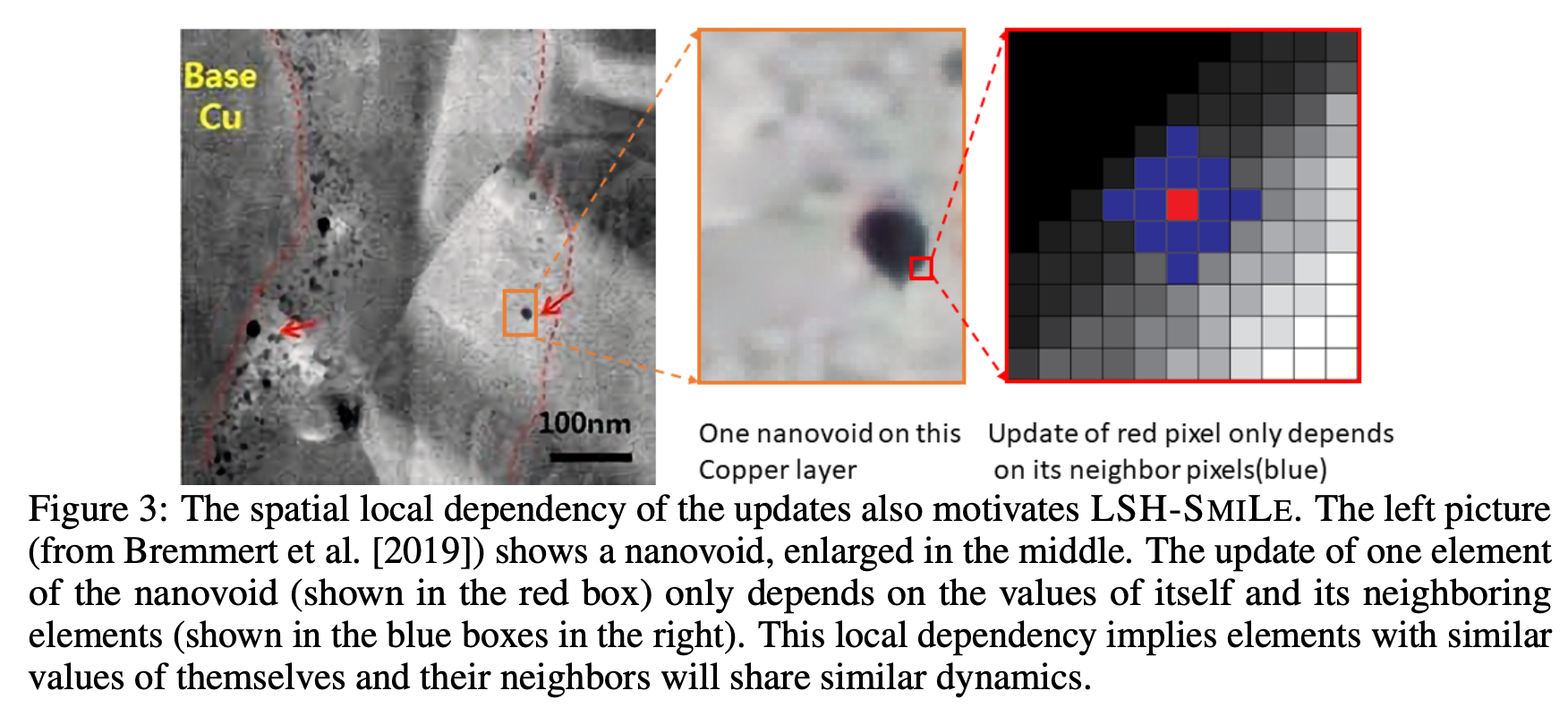
Chonghao Sima, Yexiang Xue NeurIPS, 2021 paper / bibtex We propose LSH-SMILE, a unified framework that leverages locality sensitive hashing to scale up both forward simulation and backward learning of PDE-based physics systems. By hashing elements with similar dynamics into shared buckets and processing them collectively, LSH-SMILE reduces complexity to the number of non-empty hash buckets. We provide theoretical error bounds and demonstrate comparable simulation quality with drastically less time and space, enabling gradient propagation over longer durations for improved learning. |
Patents |
| H. Li, Z. Li, W. Wang, C. Sima, L. Chen, Y. Li, Y. Qiao, J. Dai. Image Processing Method, Apparatus and Device, and Computer-Readable Storage Medium. US Patent 12,469,277, 2025. |
| H. Li, L. Chen, S. Gao, J. Yang, Y. Qiu, C. Sima, T. Li, J. Zeng, Y. Li, H. Wang, J. Yan, P. Luo, Y. Qiao. Method for Training Autonomous Driving Model, Electronic Device, and Storage Medium. US Patent App. 18/936,908, 2025. |
| H. Li, L. Chen, S. Gao, J. Yang, Y. Qiu, C. Sima, T. Li, J. Zeng, Y. Li, H. Wang, J. Yan, P. Luo, Y. Qiao. Method for Training Autonomous Driving Model, Method for Predicting Autonomous Driving Video, Electronic Device, and Storage Medium. US Patent App. 18/888,671, 2025. |
Awards |
| Best Paper Award (1/9155), CVPR 2023, for the UniAD paper "Planning-oriented Autonomous Driving". |
| Best Paper Finalist (29/4306), IROS 2025, for the "AgiBot World Colosseo" paper. |
| Outstanding Reviewer (232/7000), CVPR 2023. |
| BEVFormer ranked 1st (1/300) on Waymo Open Challenge 2022, 3D Camera-only Detection Track. |
| BEVFormer ranked 1st (1/81) on nuScenes detection leaderboard with camera-only modality, at the time of submission. |
Experience |
|
NVIDIA, Santa Clara, USA — Deep Learning Intern, Autonomous Vehicle Applied Research
Apr. 2024 – Dec. 2024 Mentored by Dr. José M. Álvarez and Dr. Zhiding Yu. Research and development of a test-time training pipeline for end-to-end autonomous driving planner to improve performance on safety-critical scenarios. |
|
Shanghai AI Lab, Shanghai, China — Research Intern, OpenDriveLab
Jun. 2019 – Mar. 2024 Mentored by Prof. Hongyang Li. Research and development of 3D perception and end-to-end autonomous driving with foundation models, including bird's-eye-view representation, multi-modality fusion, 3D occupancy prediction, and vision-language model integration for driving. |
Academic ActivitiesReviewing & Service
Workshop Organization
Recorded Talks
|
PersonalOutside of research, I enjoy hiking, J-pop, scenery photography, and anime. I also play CS:GO, Genshin Impact, Honkai: Star Rail, Zenless Zone Zero, Wuthering Waves, and Arknights: Endfield. I have been a fan of Arsenal since 2009. |
|
Website template from Jon Barron. Last updated: Feb 2026. |